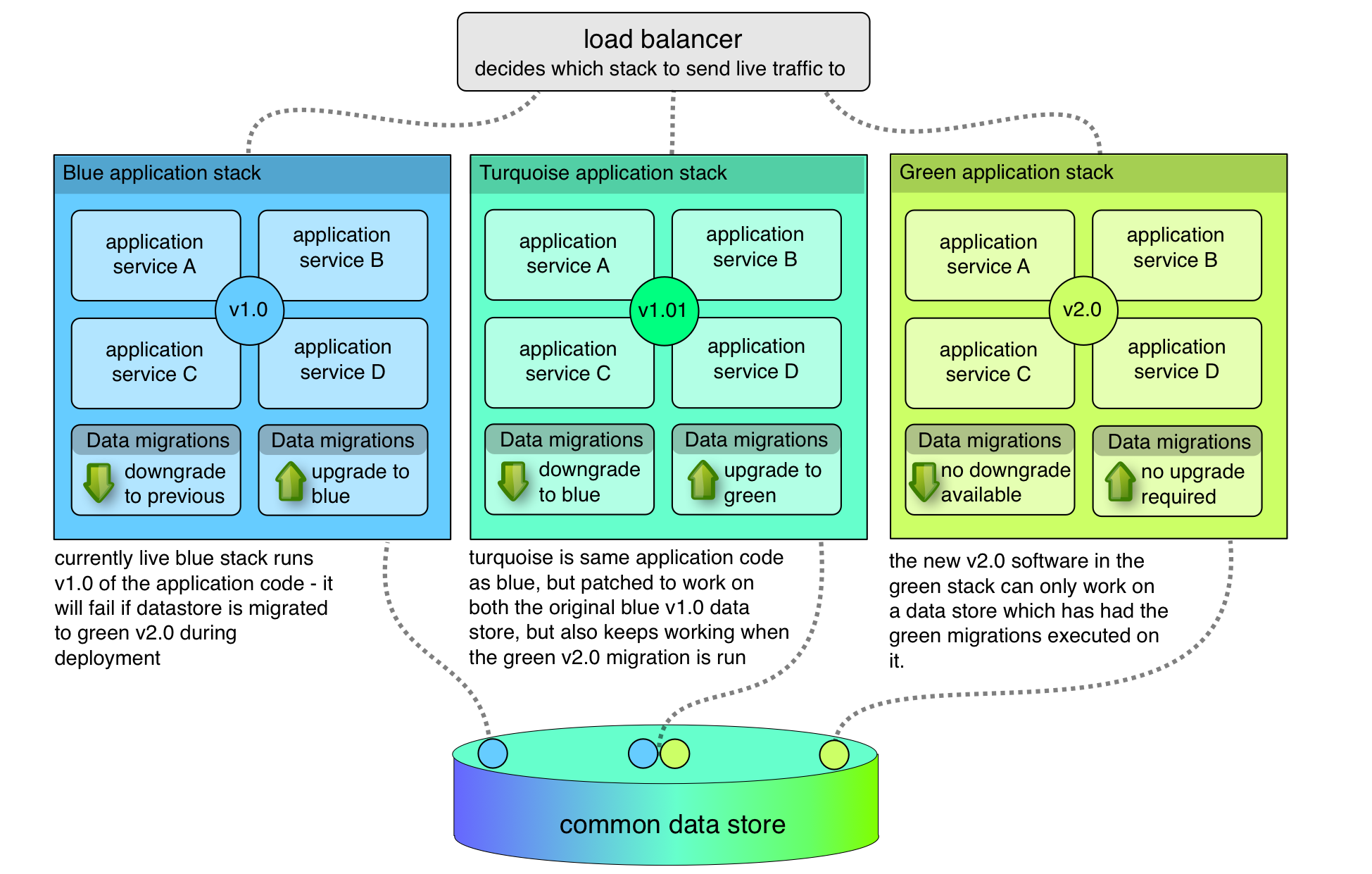
etcd is a highly available key-value store for performing service discovery and storing application configuration. It’s a key component of CoreOS – if you set up a simple CoreOS cluster you’ll wind up with etcd running on each node in your cluster.
One of the appealing things about etcd is that its API is very easy to use – simple HTTP endpoints delivering easily consumable JSON data. However, by default it’s not secured in any way.
etcd supports TLS based encryption and authentication, but the documentation isn’t the easiest to follow. In this post, I’ll share my experience of setting up a secured etcd installation from scratch.
Let’s build an etcd cluster than spans 3 continents!
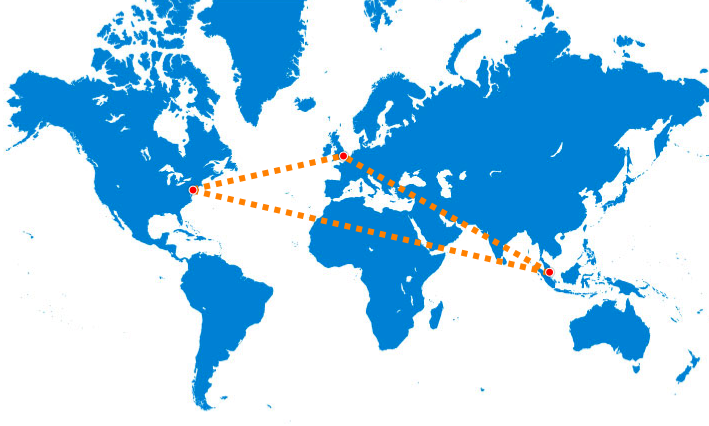
I’m going to walk through how you could build a highly available etcd cluster using 3 cheap Digital Ocean machines in London, New York and Singapore. This cluster will tolerate the failure of any one location. You could throw in San Francisco and Amsterdam and tolerate *two* failures. I’ll leave that as an exercise for the reader!
I’m going to demonstrate this using Ubuntu 15.04 rather than CoreOS – that’s simply because I wanted to learn about etcd without having CoreOS perform any configuration for me.
Ladies and gentlemen, start your engines!
Fire up 3 Ubuntu 15.04 machines. The only reason I chose 15.04 is because I wanted to use systemd, but you should be able to use whatever you prefer. If you’re not already a Digital Ocean customer, use this referral link for a $10 credit – that’ll let you play with this setup for a couple of weeks.
Each machine need only be their most basic $5/mo offering – so go ahead and create a machine in London, New York and Singapore.
You need to know their IPs and domain names – for the rest of this post I’ll refer to them as ETCD_IP1..3 and ETCD_HOSTNAME1..3. Note that you don’t need to set up DNS entries, you just need the name to create the certificate signing request for each host.
Creating a certificate authority
To create the security certificates we need to set up a Certificate Authority (CA). There’s a tool called etcd-ca we can use do this.
There’s no binary releases of etcd-ca available, but it’s fairly straightforward to build your own binary in a golang docker container.
#get a shell in a golang container docker run -ti --rm -v /tmp:/out golang /bin/bash #build etcd-ca and copy it back out git clone https://github.com/coreos/etcd-ca cd etcd-ca ./build cp /go/etcd-ca/bin/etcd-ca /out exit #now we have etcd-ca in /tmp ready to copy wherever we need it cp /tmp/etcd-ca /usr/bin/
Now we can initialise our CA. To keep things simple, I’ll use an empty passphrase
etcd-ca init --passphrase ''
This will setup the CA and store its key in .etcd-ca – you can change where etcd-ca stores such data with the –depot-path option.
Create certificates
Now we have a CA, we can create all the certificates we need for our cluster.
etcd-ca new-cert --passphrase '' --ip $ETCD_IP1 --domain $ETCD_HOSTNAME1 server1 etcd-ca sign --passphrase '' server1 etcd-ca export --insecure --passphrase '' server1 | tar xvf - etcd-ca chain server1 > server1.ca.crt etcd-ca new-cert --passphrase '' --ip $ETCD_IP2 --domain $ETCD_HOSTNAME2 server2 etcd-ca sign --passphrase '' server2 etcd-ca export --insecure --passphrase '' server2 | tar xvf - etcd-ca chain server2 > server2.ca.crt etcd-ca new-cert --passphrase '' --ip $ETCD_IP3 --domain $ETCD_HOSTNAME3 server3 etcd-ca sign --passphrase '' server3 etcd-ca export --insecure --passphrase '' server3 | tar xvf - etcd-ca chain server3 > server3.ca.crt
The keys and certificates are retained in the depot directory, but the export will have created the files we need on each of our etcd servers as serverX.crt and serverX.key.insecure. We also create a CA chain in serverX.ca.crt
We also need a client key which we’ll use with etcdctl. etcd will reject client requests if they aren’t using a certificate signed by your CA, which is how we’ll be preventing unauthorized access to the etcd cluster.
etcd-ca new-cert --passphrase '' client etcd-ca sign --passphrase '' client etcd-ca export --insecure --passphrase '' client | tar xvf -
This will leave us with client.crt and client.key.insecure
Setting up each etcd server
Here’s how we set up server 1. First, we install etcd
#install curl and ntp to keep our clock in sync apt-get update DEBIAN_FRONTEND=noninteractive apt-get -y install curl ntp #now grab binary release of etcd curl -L https://github.com/coreos/etcd/releases/download/v2.1.0-alpha.0/etcd-v2.1.0-alpha.0-linux-amd64.tar.gz -o etcd.tar.gz tar xfz etcd.tar.gz #install etcd and etcdctl, then clean up cp etcd-v*/etcd* /usr/bin/ rm -Rf etcd* #create a directory where etcd can store persistent data mkdir -p /var/lib/etcd
Copy the server1.crt, server1.key.insecure, server1.ca.crt we created earlier to /root. Now we’ll create a systemd unit which will start etcd in /etc/systemd/system/etcd.service
[Unit] Description=etcd After=network.target [Install] WantedBy=multi-user.target [Service] #basic config Environment=ETCD_DATA_DIR=/var/lib/etcd Environment=ETCD_NAME=etcd1 Environment=ETCD_LISTEN_PEER_URLS=https://$ETCD_IP1:2380 Environment=ETCD_LISTEN_CLIENT_URLS=https://$ETCD_IP1:2379 Environment=ETCD_ADVERTISE_CLIENT_URLS=https://$ETCD_IP1:2379 #initial cluster configuration Environment=ETCD_INITIAL_CLUSTER=etcd1=https://$ETCD_IP1:2380,etcd2=https://$ETCD_IP2:2380,etcd3=https://$ETCD_IP3:2380 Environment=ETCD_INITIAL_CLUSTER_TOKEN=your-unique-token Environment=ETCD_INITIAL_CLUSTER_STATE=new Environment=ETCD_INITIAL_ADVERTISE_PEER_URLS=https://$ETCD_IP1:2380 #security Environment=ETCD_TRUSTED_CA_FILE=/root/server1.ca.crt Environment=ETCD_CERT_FILE=/root/server1.crt Environment=ETCD_KEY_FILE=/root/server1.key.insecure Environment=ETCD_CLIENT_CERT_AUTH=1 Environment=ETCD_PEER_TRUSTED_CA_FILE=/root/server1.ca.crt Environment=ETCD_PEER_CERT_FILE=/root/server1.crt Environment=ETCD_PEER_KEY_FILE=/root/server1.key.insecure Environment=ETCD_PEER_CLIENT_CERT_AUTH=1 #tuning see https://github.com/coreos/etcd/blob/master/Documentation/tuning.md Environment=ETCD_HEARTBEAT_INTERVAL=100 Environment=ETCD_ELECTION_TIMEOUT=2500 ExecStart=/usr/bin/etcd Restart=always
The etcd documentation recommends setting the election timeout to around 10x the ping time. In my test setup, I was seeing 250ms pings from London to Singapore, so I went for a 2500ms timeout.
It should be clear how to adjust that unit for each server – note that the ETCD_INITIAL_CLUSTER setting is the same for each server, and simply tells etcd where it can find its initial peers.
Now we can tell the system about our new unit and start it
systemctl daemon-reload systemctl enable etcd.service systemctl restart etcd.service
Do that on all three servers and you’re up and running!
Setting up etcdctl
We can set up some environment variables on the server so that etcdctl uses our client certificate. Copy the client.crt to /root and create this file in /etc/profile.d/etcd.sh so that you have these environment variables on each login.
export ETCDCTL_CERT_FILE=/root/client.crt export ETCDCTL_KEY_FILE=/root/client.key.insecure export ETCDCTL_CA_FILE=/root/server1.ca.crt export ETCDCTL_PEERS=https://$ETCD_IP1:2379,https://$ETCD_IP2:2379,https://$ETCD_IP3:2379
Log back in and you should be able to play with etcdctl
etcdctl set /foo bar etcdctl get /foo
Here’s how you could talk to a specific node with curl
curl --cacert /root/server1.ca.crt \ --cert /root/client.crt \ --key /root/client.key.insecure \ -L https://$ETCD_IP1:2379/v2/keys/foo
What next?
As it stands, you could use this setup as a secure for replacement for https://discovery.etcd.io to bootstrap a CoreOS cluster. You could also use this as the basis for a CoreOS cluster which is distributed across multiple datacentres.
While exploring this, I found the follow pages useful
- CoreOS Etcd and Fleet with Encryption and Authentication – this focusses on setting up CoreOS with a secured etcd setup
- Deploying CoreOS cluster with etcd secured by TLS/SSL by Marek Skrobacki. He shows how you can create your certificates using openssl tools rather than etcd-ca
- CoreOS manual page on etcd security